
技术艺术
周四,微软研究人员宣布了一种新的文本到语音人工智能模型,称为 谷 当给定三秒钟的音频样本时,它可以非常接近地模仿人的声音。 一旦它学会了一种特定的声音,VALL-E 就可以合成那个人说任何话的声音——并以一种试图保持说话者情绪基调的方式进行合成。
它的创建者预计 VALL-E 可用于高质量的文本到语音应用程序、语音编辑,其中可以根据文本抄本编辑和更改一个人的录音(让他们说出他们最初没有说的话),以及与其他人工智能模型(如 GPT-3.
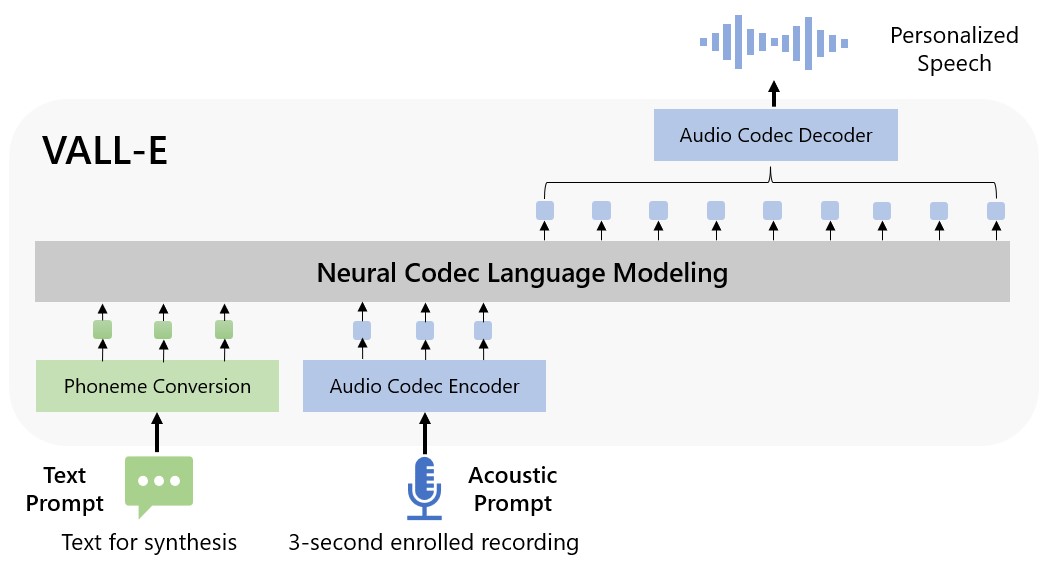
微软将 VALL-E 称为“神经编码语言范式”,它建立在一种称为 EnCodec 的技术之上, 宣告死亡 2022 年 10 月。与通常通过处理波形合成语音的其他文本转语音方法不同,VALL-E 从文本和语音提示中生成单独的语音编码器。 它基本上分析了一个人的声音,借助 EnCodec 将该信息分解为单独的组件(称为“令牌”),并使用训练数据来匹配它“知道”的那个人如果用其他语言说话会听起来像什么三秒钟示例之外的短语。 或者正如微软所说的那样 瓦力纸:
对于自定义语音分组(例如,非shot TTS),VALL-E生成相应的语音代码模态到录制的3秒录音语音代码和语音提示,分别约束说话人和内容信息。 最后,生成的音频代码用于将最终波形与相应的神经解码器分组。
微软将VALL-E的语音合成能力训练成一个声音库,由Meta编译,名为 自由精简版. 它包含来自 7,000 多名演讲者的 60,000 小时英语口语,其中大部分来自 图书馆之声 公共领域有声读物。 为了让 VALL-E 获得好成绩,三秒样本中的声音必须与训练数据中的声音相匹配。
在谷歌 网站示例Microsoft 提供了数十个 AI 模型的音频示例。 在样本中,“扬声器提示”是为 VALL-E 提供的必须模仿的三秒声音。 “基本事实”是同一位说话者为了比较目的而说出特定陈述的预先存在的录音(有点像实验的“控制”)。 “Baseline”是通过传统的文本到语音合成方法提供的合成示例,样本“VALL-E”是VALL-E模型的输出。
微软
在使用 VALL-E 生成这些结果时,研究人员仅将一个三秒钟的“扬声器提示”样本和一个文本字符串(他们想让声音说出的内容)输入 VALL-E。 因此,将“Ground Truth”样本与“VALL-E”样本进行比较。 在某些情况下,两个样本非常接近。 一些 VALL-E 结果似乎是计算机生成的,但其他一些可能会被误认为是人类语音,而这正是该模型的目标。
除了保留说话者的音色和情绪基调外,VALL-E 还可以模拟语音样本的“声学环境”。 例如,如果样本来自电话,音频输出将在其合成输出中模拟电话的声学和频率特性(这是一种奇特的说法,它听起来也像电话)。 和微软 样品 (在“多样性综合”部分)表明,VALL-E 可以通过改变生成过程中使用的随机种子来生成音高变化。
或许由于 VALL-E 的恶作剧和欺骗能力,微软一直没有提供 VALL-E 代码供其他人试用,所以我们一直无法测试 VALL-E 的能力。 研究人员似乎意识到这项技术可能造成的潜在社会危害。 在论文的结尾,他们写道:
“因为 VALL-E 可以合成保留说话者身份的语音,它可能存在模型滥用的潜在风险,例如欺骗语音识别或冒充特定说话者。为了减轻这些风险,可以建立一个检测模型来区分是否已合成特定扬声器。VALL-E 的原声带。我们还将 微软人工智能原理 在实际开发模型时。

“极端问题解决者。旅行忍者。典型的网络迷。浏览器。作家。读者。无法治愈的组织者。”



More Stories
苹果 iOS 27 曝光全新 Siri 界面:AI 搜索与聊天功能进一步整合
OpenAI押注“速度革命”:人工智能推理竞赛进入新阶段
屏下人脸识别技术迈出关键一步:全面屏手机时代或将真正到来