
斯坦福大学以人为中心的人工智能(你好) 最近发布了年度全球人工智能指数,该指数回顾了人工智能研究、伦理、投资和商业使用的趋势。 由于它长达 384 页,令人惊叹,我们将在接下来的几周内分期回顾 2023 年 AI 指数。 本周我们来看看技术发展——主要是“人工智能到底有多好”?
谁在做人工智能的研发?
HAI 的基本发现是,人工智能研究发生了从大学部门到私营部门的巨大转变。 直到 2014 年,大多数机器学习系统都是由学术界发布的。 到 2022 年,将有 32 个重要的商业机器学习系统,而学术界只有三个。
人工智能的“私有化”很可能是不可逆转的,因为正如 HAI 指出的那样,“[b]构建最先进的人工智能系统越来越需要大量的数据、计算能力和资金——行业参与者拥有的资源比非营利组织和学术界拥有的更多。 例如,谷歌在 2022 年推出的 PaLM 拥有 5400 亿个参数,是 2019 年发布的 GPT-2 的近 360 倍,而 PaLM 的训练成本为 810 万美元,而 GPT-2 的训练成本为 5 万美元。
毫不奇怪,开发的重点一直放在语言大型模型 (LLM) 上,例如 ChatGPT。 在 2022 年发布的 36 个重要的 AI 机器学习系统中,LLM 系统是最受欢迎的系统类别:发布了 23 个重要的 LLM 系统,几乎是下一个最受欢迎的系统类型多媒体系统的六倍,有远见的只有 2 个新专家和 2 个新的现代系统。
中国在寻找人工智能方面领先于世界其他地区。 AI 文章产量最高的前 10 名机构中有 9 名来自中国(麻省理工学院排名第 10)。 2022 年,中国作者占 AI 出版物的近 40%。
然而,在 2022 年发布的 36 个重要机器学习系统中,有 16 个来自美国,8 个来自英国(表明英国政府在大力推动 AI 方面取得了一些成功),3 个来自英国。欧盟委员会为促进人工智能所做的同样艰苦的努力尚未取得成果),只有三个来自中国。
不过,这并不是低估中国研发的AI模型:
- GLM-130B 中英文双语硕士HAI 由清华大学的研究人员创建,称其“令人印象深刻”,其他人称其优于 OpenAI 的 GPT-3 和谷歌的 PaLM。
- 在医学图像分割中,AI系统对医学图像中的病灶或器官等对象进行分割,性能通过骰子平均值来衡量,表示AI系统识别出的息肉片段与实际息肉片段的重叠程度. 2022 年表现最好的模型是由一位中国研究人员创建的,平均骰子得分为 94.1%。
作为与“AI 民族主义”的鲜明对比,HAI 还强调了 AI 领域跨国合作的重要性:“[c]学者、研究人员、行业专家和其他人之间的合作是现代 STEM(科学、技术、工程和数学)发展的关键组成部分,它可以加速新思想的传播和研究团队的成长。”
如下图所示,大多数跨国合作是在中美研究人员之间进行的,但或许反映了地缘政治的逆风,2020 年至 2021 年美中合作总数仅增长了 2.1%,这是最小的年度生长。 自 2010 年以来的利率。
另外,澳大利亚与中国研究人员和美国研究人员的合作是全球最广为人知的合作之一,这表明澳大利亚人工智能研究人员可能远远超出他们的能力,并成功应对了这些不利的地缘政治条件。
人工智能有多好?
尽管对于像 ChatGPT 这样的生成式 AI 模型可以做什么有很多炒作,但 HAI 对 2022 年 AI 能力的进步有更清醒的评估:“AI 继续发布最新发现,但在这一年中——整体改进在许多基准测试中仍然处于边缘。”
HAI 使用一组与任务相关的基准来测试 AI 性能,如下图所示,虽然自基准首次用于 AI 以来性能有了非常大的提升(条形的蓝色部分),但 year- 2022 年的同比改善是递增的 非常(条形图的紫色部分):除 7 项标准外,报告的改善均低于 5%。
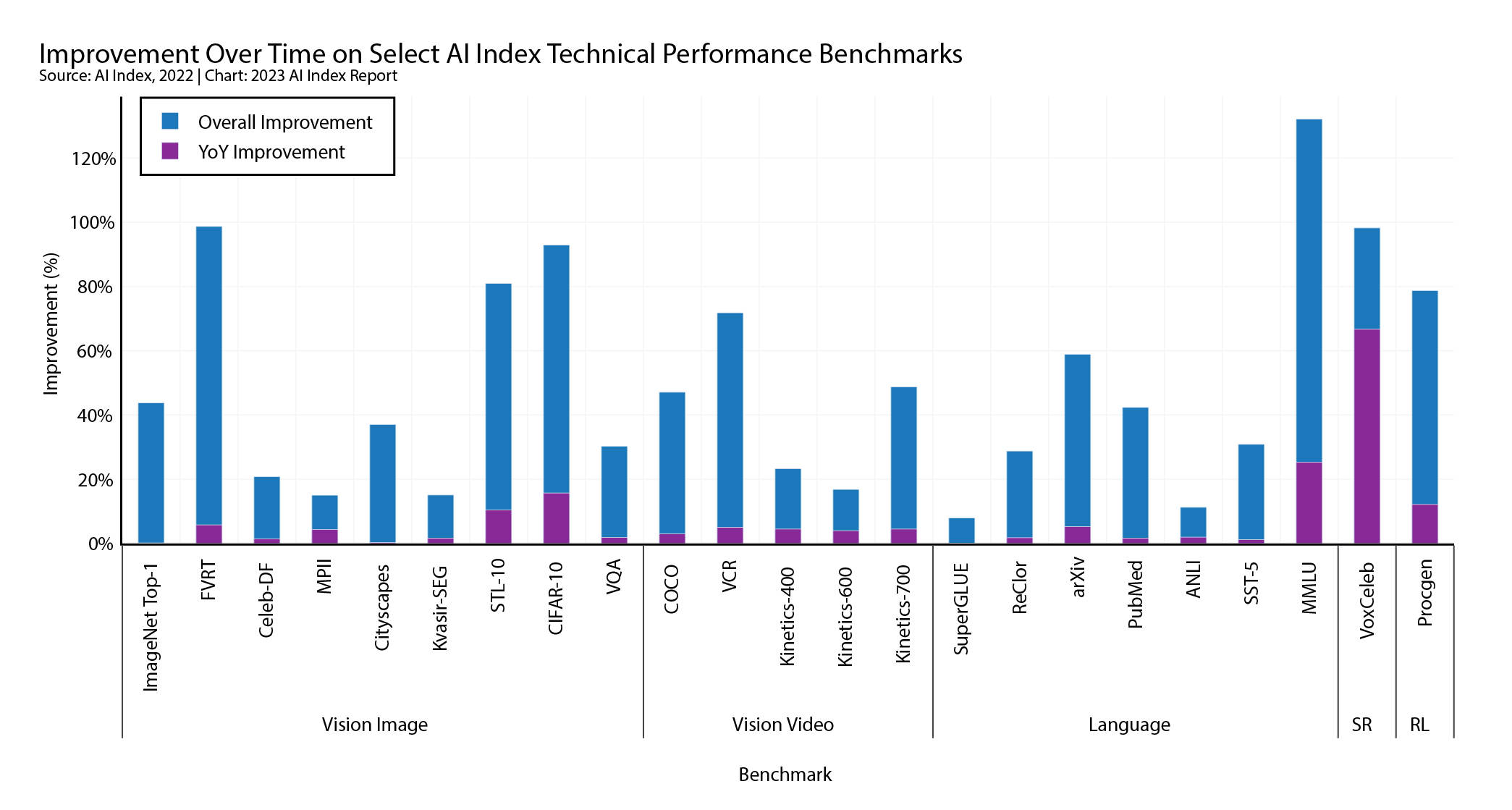 举个具体的例子,2020年,美国研究人员公布了AI语音识别(文字转文本)的最佳成绩,其模型达到了0.1%的错误率。 但这与中国研究人员去年的最新发现相比,错误率仅下降了 0.28 个百分点。
举个具体的例子,2020年,美国研究人员公布了AI语音识别(文字转文本)的最佳成绩,其模型达到了0.1%的错误率。 但这与中国研究人员去年的最新发现相比,错误率仅下降了 0.28 个百分点。
这是否意味着人工智能已经走到了“砖墙”? 是和否 – 似乎有 4 种不同的情况发生。
熟能生巧
在 AI 的积极方面,HAI 表示“达到基准饱和的速度正在加快。” 这意味着人工智能相对于某些基准的表现现在非常好 – 非常接近完美 – 任何进一步的改进,如果不是非常小,都是不可避免的。
例如,HAI 通过美国国家标准与技术研究院的人脸识别供应商测试跟踪 AI 人脸识别的进展,该测试测试不同的人脸识别算法在各种国土安全任务中的表现如何,例如识别贩卖儿童受害者和交叉检查。的签证照片。 人脸检测能力由错误不匹配率(核磁共振). 截至 2022 年,性能最好的模型的错误率低于 1%,在某些数据集中低至 0.06%。 当然,提高准确性本身并不是使用 FRT 的基础,因为围绕它的使用需要更多的隐私和公平考虑。
人工智能已经超越了一些基准
再次从 AI 的积极方面来看,HAI 指出,许多现有的语言标准并未严格测试语言模型在不同领域应用所学知识的能力。 这种批评与新一代人工智能生成模型尤其相关,这些模型可用于许多不同领域,从医疗诊断到保险理赔处理再到撰写大学论文。
所以 HAI 使用一种称为通用多任务语言理解的标准(MMLU),它在人文、STEM 和社会科学的 57 个不同学科中评估零样本或少样本设置中的模型。
HAI 发现 Gopher、Chinchilla 和 PaLM 的变体在 MMLU 上发布了最新的结果,并且同比改进的速度在 HAI 的基准测试中是最快的。
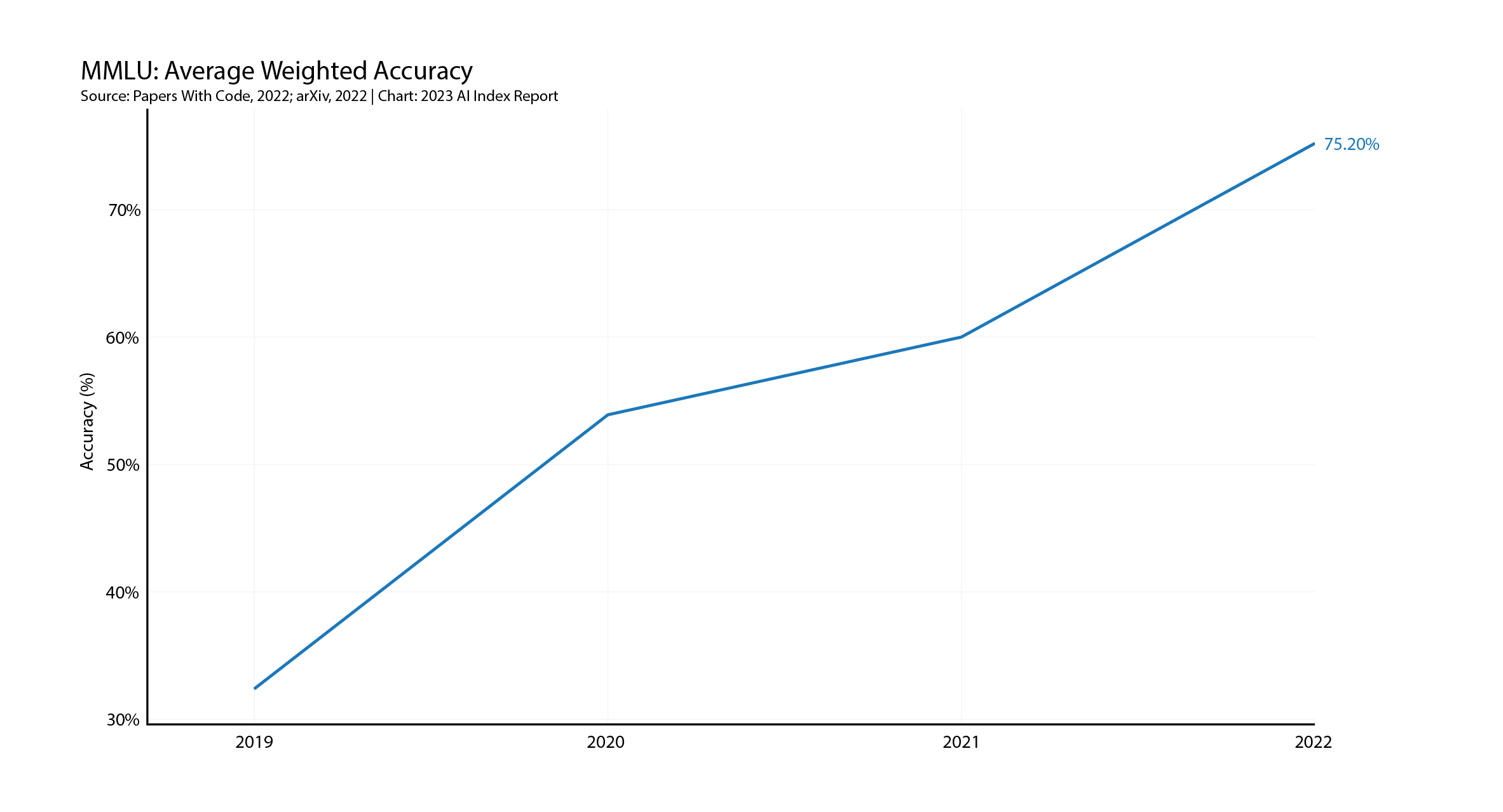
人工智能在思考中挣扎
在 AI 的不利方面,HAI 指出,虽然“[l]焦虑模型继续提高它们的生成能力,……新的研究表明它们仍然在与复杂的计划任务作斗争。”或者,正如 Facebook 首席人工智能科学家 Yan Liken 所说,AI 的常识不亚于家猫.
这可以通过比较 2023 AI 指数报告中的两个基准来说明。
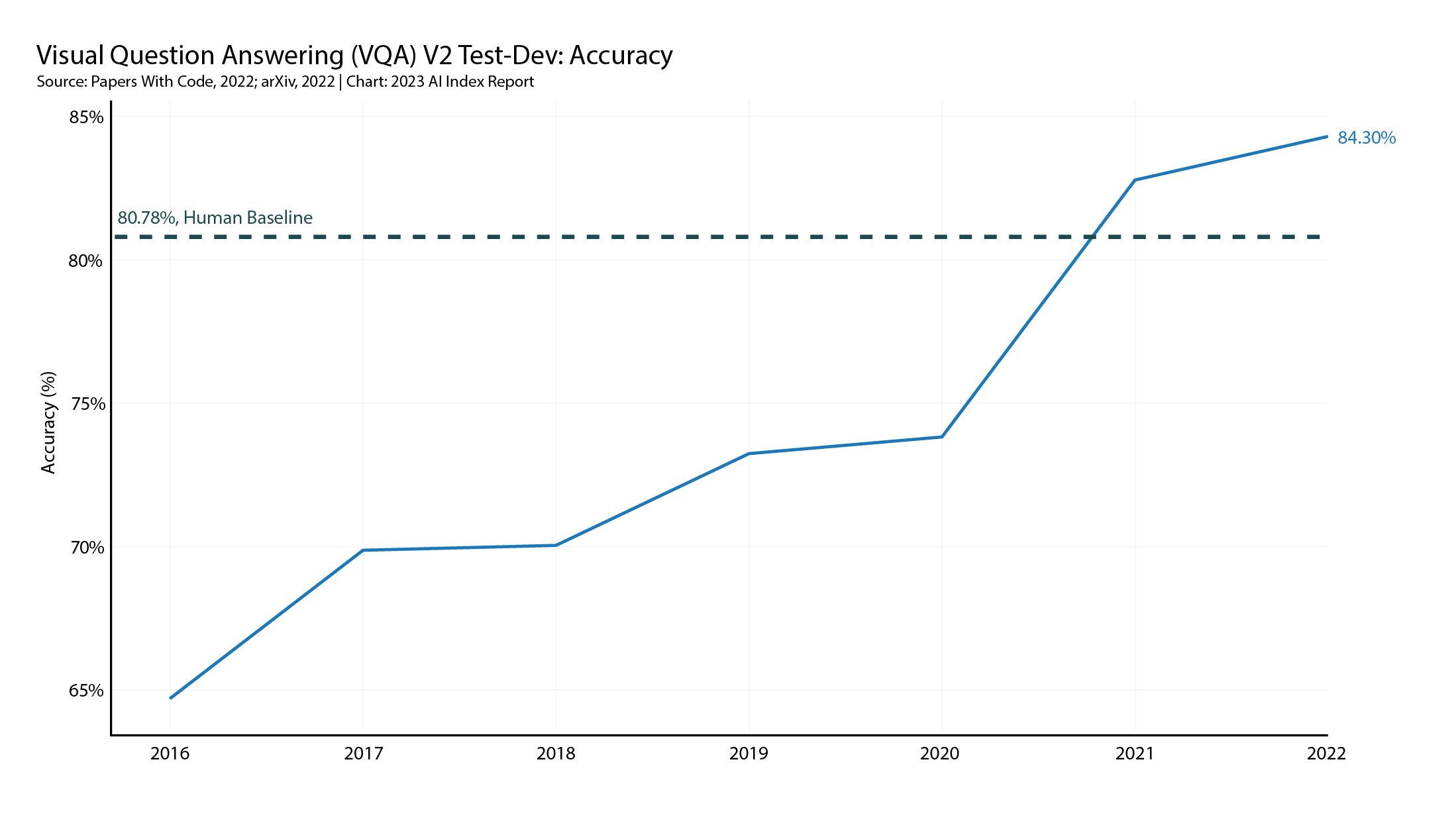
第一个标准是回答视觉问题的挑战(VQA) 用关于图像的开放文本问题测试 AI 系统:例如如下所示:

表现最好的模型是 PaLI,这是一种由谷歌研究人员制作的多模态模型,其得分优于人类基准,如下所示:
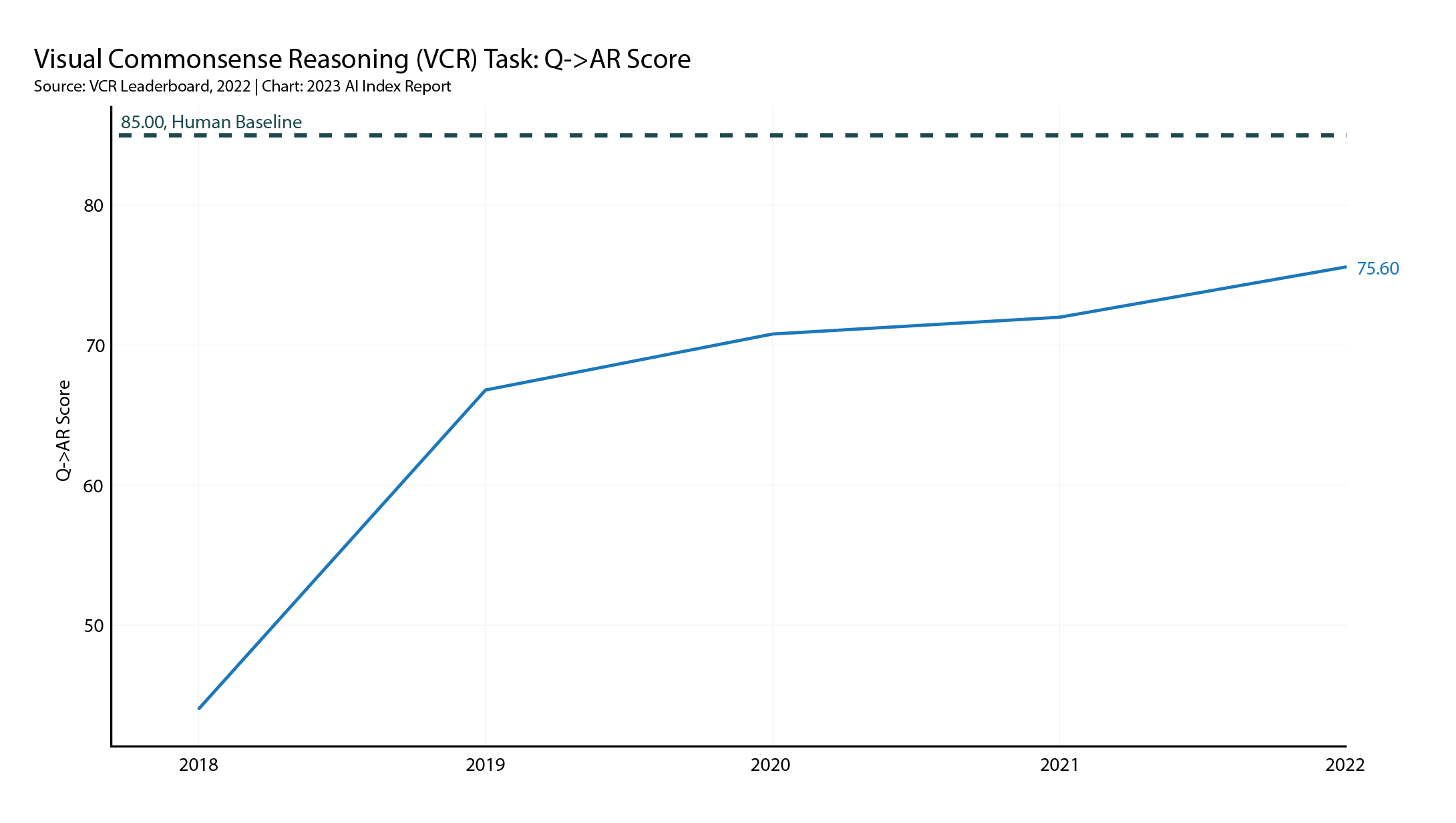
第二个标准是视觉常识推理(录像机),这是一个相对较新的标准,其中 AI 系统必须像 VQA 一样回答图像提供的问题,但 AI 必须进一步确定答案选择背后的原因。
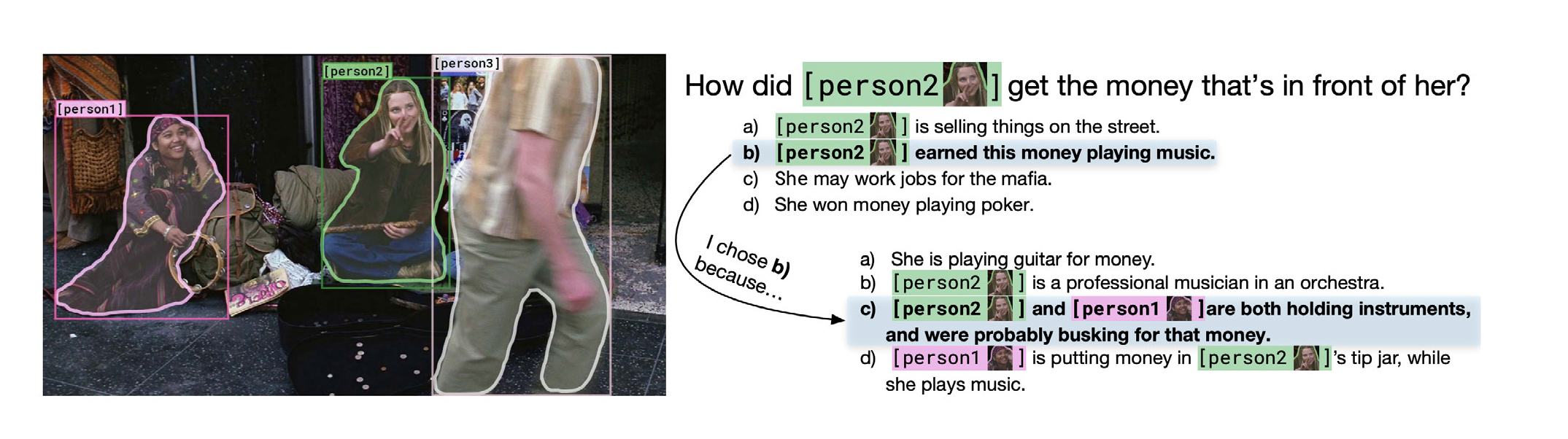
如下图所示,在这个更复杂的推理测试中,人工智能系统的运行始终低于人类测量水平。 HAI 指出,“VCR 是本报告中考虑的少数几个人工智能系统没有超越人类表现的视觉基准之一。”
接下来的两期将研究 2023 年 AI 指数中关于 AI 伦理和 AI 投资与商业使用的数据。
人工智能正在努力理解我们
最后,再次从人工智能的消极方面来看,它难以准确识别人类情绪。
情感分析 AI 应用语言技术来识别给定文本中的情感。 许多公司使用它来更好地了解客户评论。
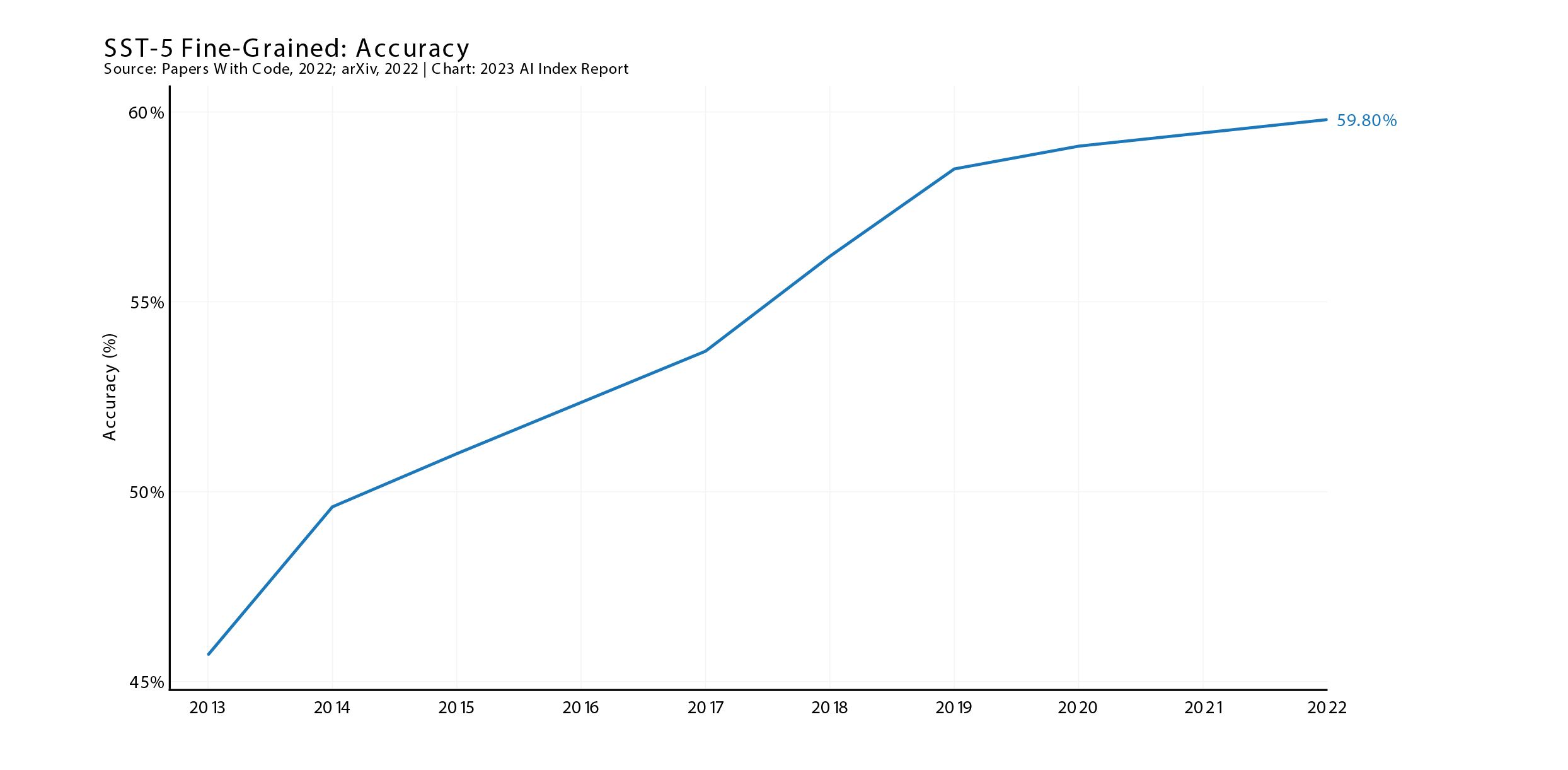
斯坦福Tribank感觉(不锈钢) 是一个数据集,包含从电影评论中提取的 11,855 个单独的句子,然后将这些句子转换为 215,154 个独特的陈述,这些陈述的感受由人类评委解释。
到 2022 年,AI 在 SST 基准上创下新高——但大型 Heinsen Routing + RoBERTa 模型仅发布了 59.8%,并且 YoY 看起来将趋于平稳。
人工智能作为新的“Q”。
HAI 发现的一个惊人发展是人工智能模型开始迅速加速科学进步。 HAI 提供的示例包括:
- 核聚变是一种更安全、更清洁的核能,它是使用一种叫做托卡马克的机器来实现的,它控制并包含热氢等离子体。 问题是这些机器产生的等离子体不稳定,需要持续监控。 2022 年,DeepMind 的研究人员开发了一种强化学习算法来发现最佳托卡马克管理例程。
- 使用常规方法进行抗体检测通常需要大量时间和资源,通常会导致抗体效果不佳(这需要研究人员一次又一次地归零)。 生成式 AI 用于通过零火法生成抗体,其中抗体是通过单轮模型生成生成的,无需进一步优化。 这些人工智能生成的抗体也很强大。 这种基于人工智能的方法应该会大大加速药物发现。
HAI 还将“自生成人工智能”确定为另一个新兴趋势。 芯片制造商英伟达 (Nvidia) 使用人工智能设计了一款芯片,与之前使用标准电子设计自动化工具设计的芯片相比,体积缩小了 25%,但速度和功能同样出色。

“屡获殊荣的电视专家。僵尸爱好者。无法用拳击手套打字。培根开拓者。”



More Stories
清明假期前后出游热度攀升:景区打车需求同比增长约35%
湘BA株洲赛区开赛在即:一张票根串联40家景区,激活城市文旅消费
中国为盲人提供更多电影